Last updated on 7 months ago
前言
一个c语言文件是怎么转换成 可执行文件的呢? 中间有什么过程呢? 编译器 起着什么作用呢?
如何转换可执行文件?
我们编译的时候要么用 ide 帮我编译程序,要么自己敲命令,我们后者为例,使用gcc 编译一个c文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| hrp@ubuntu:~$ cat hello.c
#include <stdio.h>
int main() {
printf("你好,世界!\n");
//这是注释!!!
return 0;
}
hrp@ubuntu:~$ gcc hello.c -o hello
hrp@ubuntu:~$ ./hello
你好,世界!
hrp@ubuntu:~$
|
一个很简单的代码,使用 gcc 编译就可以到 二进制可执行文件,并执行;那这之间发生了什么呢?
整个编译流程可以分为4个部分
1. 预处理 (Preprocessing)
在预处理阶段,预处理器会处理源代码文件,执行诸如宏展开、头文件包含等操作,并生成一个经过预处理的中间文件
比如代码里面用到头文件 stdio.h #include <stdio.h> ,预编译的时候则会找到对应的 这个文件所在的目录; 如果有用到宏定义,会将代码中使用到的宏替换成对应的字符
预编译可以单独执行, gcc -E 即可以看到,原本的c语言文件 预处理后是什么样子的
1
2
3
4
5
6
7
8
9
10
11
12
| hrp@ubuntu:~$ cat hello.c
int main() {
int i = PI * PI;
printf("你好,世界!\n");
return 0;
}
hrp@ubuntu:~$
hrp@ubuntu:~$ gcc -E hello.c -o hello.i
|
- **查看 hello.i 发现 #include <stdio.h> 已经变成了 绝对路径 “/usr/include/stdio.h” **
- 删除了define PI的宏 也替换成了3.14159
- 删除了注释,c源码中的注释也没有
1
2
3
4
5
6
7
8
9
10
11
| #....
...
# 868 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
# 5 "hello.c"
int main() {
int 10i = 3.14159 * 3.14159;
printf("你好,世界!\n");
return 0;
}
|
2 编译 (Compiling)
编译器接收预处理后的文件,并将其转换为汇编语言,这个过程也是最为复杂一环,需要编译器的来做一些 词法分析,词法分析等相关工作(后面会分析);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| hrp@ubuntu:~$ gcc -S hello.i -o hello.s && cat hello.s
.file "hello.c"
.text
.section .rodata
.LC0:
.string "\344\275\240\345\245\275\357\274\214\344\270\226\347\225\214\357\274\201"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $9, -4(%rbp)
leaq .LC0(%rip), %rdi
call puts@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
.section .note.GNU-stack,"",@progbits
hrp@ubuntu:~$
|
预编译和编译这两个操作可以合并,是用gcc 自带的程序 (cc1)生成 汇编文件 , cc1 会输出编译器执行过程中不同阶段的时间统计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| hrp@ubuntu:~$ /usr/lib/gcc/x86_64-linux-gnu/7/cc1 hello.c
main
Analyzing compilation unit
Performing interprocedural optimizations
<*free_lang_data> <visibility> <build_ssa_passes> <opt_local_passes> <targetclone> <free-inline-summary> <whole-program> <inline>Assembling functions:
<materialize-all-clones> <simdclone> main
Execution times (seconds)
phase setup : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.00 ( 0%) wall 1179 kB (68%) ggc
phase parsing : 0.00 ( 0%) usr 0.04 (100%) sys 0.05 (83%) wall 488 kB (28%) ggc
phase opt and generate : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.01 (17%) wall 56 kB ( 3%) ggc
dump files : 0.00 ( 0%) usr 0.00 ( 0%) sys 0.01 (17%) wall 0 kB ( 0%) ggc
lexical analysis : 0.00 ( 0%) usr 0.03 (75%) sys 0.05 (83%) wall 0 kB ( 0%) ggc
parser (global) : 0.00 ( 0%) usr 0.01 (25%) sys 0.00 ( 0%) wall 320 kB (18%) ggc
TOTAL : 0.00 0.04 0.06 1733 kB
|
3 汇编 (Assembling)
汇编器接收汇编语言代码,并将其转换为机器码,生成目标文件(xxx.o);每条汇编命令都有相对于的机器码,只需逐条翻译即可;
可以使用 as 命令,也可以使用 gcc -c 命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| hrp@ubuntu:~$
hrp@ubuntu:~$ as hello.s -o hello.o
// 对于 目标文件可以用 objdump 反汇编查看
hrp@ubuntu:~$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 09 00 00 00 movl $0x9,-0x4(%rbp)
f: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 16 <main+0x16>
16: e8 00 00 00 00 callq 1b <main+0x1b>
1b: b8 00 00 00 00 mov $0x0,%eax
20: c9 leaveq
21: c3 retq
hrp@ubuntu:~$
hrp@ubuntu:~$ gcc -c hello.s -o hello.o
hrp@ubuntu:~$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 fc 09 00 00 00 movl $0x9,-0x4(%rbp)
f: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 16 <main+0x16>
16: e8 00 00 00 00 callq 1b <main+0x1b>
1b: b8 00 00 00 00 mov $0x0,%eax
20: c9 leaveq
21: c3 retq
hrp@ubuntu:~$
|
4 链接 (Linking)
链接器接收一个或多个目标文件,将它们合并在一起,并解析它们之间的符号引用, 生成可执行文件
1
2
3
4
5
| hrp@ubuntu:~$ gcc hello.o -o hello
hrp@ubuntu:~$ ./hello
你好,世界!
hrp@ubuntu:~$
|
经历了这4个步骤就完成了从c语言文本到可执行文件的转换
编译器具体做了什么?
简单的来说,编译器的工作就是把自然语言转换为机器语言,可以理解就是一个翻译官,而且这个翻译官做了翻译的被背后边很多优化! 翻译的过程可以分为以下六个步骤
词法分析(Lexical Analysis)
词法分析器会跟据不同语言的此法规则,将源代码分解成一个个的词法单元(tokens),如关键字、标识符、运算符;
从左往右逐个字符地扫描源程序,产生一个个的单词符号。也就是说,它会对输入的字符流进行处理,再输出单词流。执行词法分析的程序即词法分析器,或者说扫描器。
语法分析(Syntax Analysis)
语法分析器根据词法分析器得到的词法单元,构建出抽象语法树(Abstract Syntax Tree,AST),表示程序的结构。
语义分析(Semantic Analysis)
语义分析器检查代码的语义正确性,包括类型匹配、变量声明、函数调用等(检查你的代码有咩有按照规则来写)
优化(Optimization)
优化器对生成的抽象语法树进行各种优化操作,如优化一些汇编指令、循环优化等,以提高程序的执行效率
代码生成(Code Generation)
代码生成器将优化后的抽象语法树转换成目标代码,通常是汇编代码或者机器代码。
链接(Linking)
如果编译器生成的是目标文件而不是可执行文件,那么链接器会将多个目标文件链接成一个可执行文件。链接器还负责解析外部函数和变量的引用,将其与其他文件中的定义进行连接。
前面为五个步骤是生成了 目标文件,目标文件只要语法正确都可以生成
比如 hello.c 没有main 函数,但是也可以生成目标文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| hrp@ubuntu:~$ cat hello.c
#include <stdio.h>
void print_hello_1() {
printf("print_hello_1 function!\n");
}
void print_hello_2() {
printf("print_hello_1 function!\n");
}
hrp@ubuntu:~$
hrp@ubuntu:~$ gcc -c hello.c -o hello.o
hrp@ubuntu:~$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <print_hello_1>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <print_hello_1+0xb>
b: e8 00 00 00 00 callq 10 <print_hello_1+0x10>
10: 90 nop
11: 5d pop %rbp
12: c3 retq
0000000000000013 <print_hello_2>:
13: 55 push %rbp
14: 48 89 e5 mov %rsp,%rbp
17: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 1e <print_hello_2+0xb>
1e: e8 00 00 00 00 callq 23 <print_hello_2+0x10>
23: 90 nop
24: 5d pop %rbp
25: c3 retq
|
我需要调用 hello.c 里面的 print_hello_1 函数应该怎么做呢?(其实这种场景很常见,一个项目中可能会分为很多功能模块,主函数会调用其他模块的函数)
我在 main.c 文件里面调用了 print_hello_1 函数,这main.c 文件也是可以生成目标文件,可以可能到有 cllaq 跳转指令 ,callq 指令的作用是跳转到目标函数的地址,从反汇编文件看, 是跳转到了 目标地址为 e 的函数,目前只是单独编译 main.c 的文件,还没有涉及到 hello.c 文件;
最后 gcc -c 生成可执行文件,执行结果符合预期,调用了 print_hello_1 , 那问题来了,main.o 中 callq e <main+0xe> ,是怎么跳转到 hello.o 中的print_hello_1呢?
为了解决这个问题,编译器最后会把 多个模块根据一定的规则,以及主函数需要调用哪些模块的代码,将其组合到一起,最后形成可执行文件,这做法也就是 链接
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| hrp@ubuntu:~$ cat main.c
#include <stdio.h>
// 声明外部函数
extern void print_hello();
int main() {
print_hello_1();
return 0;
}
hrp@ubuntu:~$ gcc -c main.c -o main.o -w
hrp@ubuntu:~$ objdump -d main.o
main.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: b8 00 00 00 00 mov $0x0,%eax
// 在 callq
9: e8 00 00 00 00 callq e <main+0xe>
e: b8 00 00 00 00 mov $0x0,%eax
13: 5d pop %rbp
14: c3 retq
hrp@ubuntu:~$
hrp@ubuntu:~$ gcc -c main.o hello.o -o main
hrp@ubuntu:~$ ./main
print_hello_1 function!
|
链接
背景
在汇编语言出现之前,当时没有内存之类的存储介质,程序是以打孔的形式存放在纸带上,计算机在运行程序时会直接从纸带的开头开始读取,每读取到一条指令就执行一条指令。
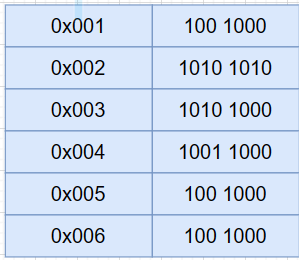
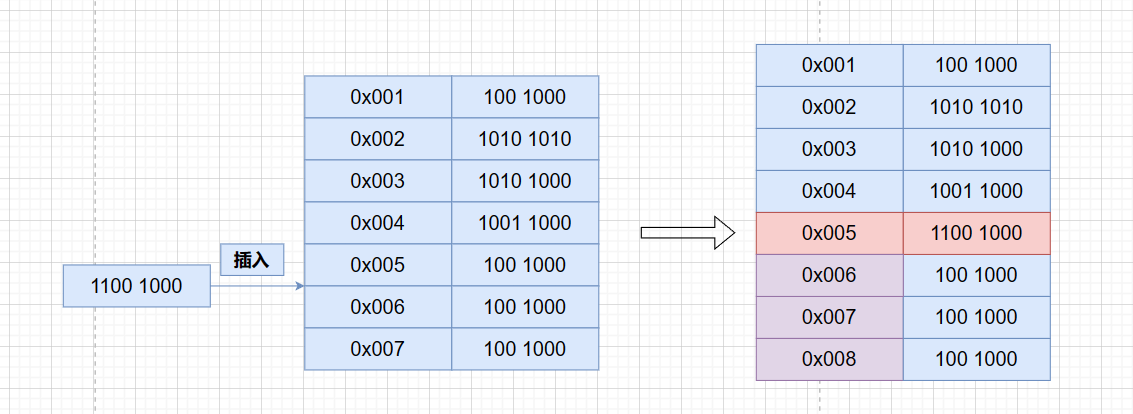
然而,程序经常需要进行修改。例如,插入几条指令在第四条指令和第五条指令之间,这会导致第五条指令后面的指令位置发生变化,整个程序的地址都需要重新计算。工程师必须重新计算并修改纸带上的指令位置,这个过程称为重定位。 如果程序很大,涉及到多个纸带,那么即使是一个简单的修改也会导致大量的工作量。
后来人们发明了汇编语言,它更易读,开发人员不再需要记住每个机器码。
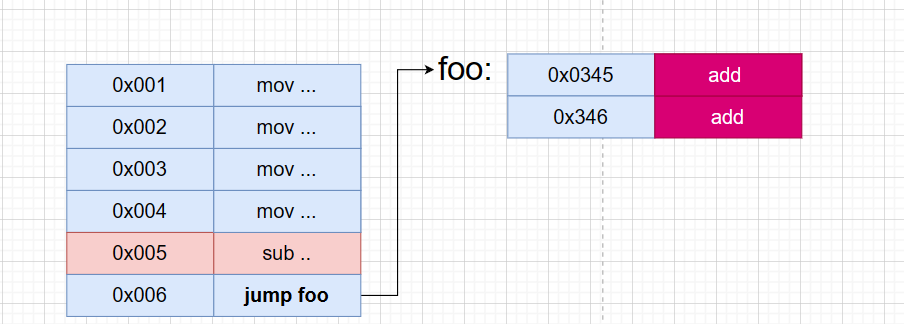
此外,汇编语言还允许使用符号来表示地址。例如, 可以用符号“foo”代表地址0x001,这样可以通过写”jump foo” 来跳转到地址0x0001的位置,有了这个语法糖之后,执行函数,只要知道函数代码的地址,直接用 jump 跳转过去在执行,原本在第五条指令前插入指令,会影响后面的代码,假如第五条指令后的内容,使用 jump XXX 的方式来执行,只要 foo 地址不变化,那我无论在前面加入多少条都不会影响后面的寻址结果,foo 只是符号,就算 foo 目标地址发生了改动,只需要 把foo 指令修正到新的地址即可,这样就拜托了手动跳转地址的工作。
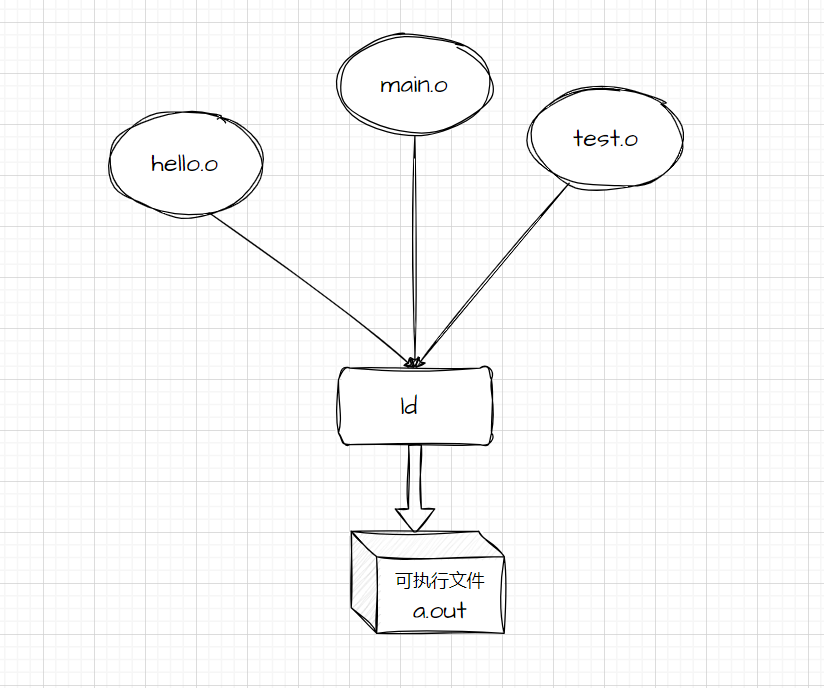
有了汇编语言之后,编程变得更加容易;一个项目可以被切割成许多模块,这些模块之间既相互依赖又相互独立。那么,模块之间如何组合?如何相互调用?模块间的变量如何访问?这时候链接器就发挥了重要作用,接下来我们将介绍它的功能和作用。
链接的定义
链接(linking)是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(或被拷贝)到存储器并执行; 此外外 链接可以执行于编译时(compile time),也就是在源代码被翻译成机器代码时;也可以执行于加载时,也就是在程序被加载器(loader)加载到存储器并执行时;甚至执行于运行时(run time),这也就是校招面试经常问到的静态编译和动态编译;
链接 解决的问题是什么呢?
解决了符号引用问题:
在编写程序时,经常会引用其他文件中定义的函数、变量或者常量。链接的一个重要作用是将这些引用与其定义进行关联,以确保程序能够正确地调用这些函数、访问这些变量和常量。
合并多个目标文件:
当程序由多个源文件编译而成时,每个源文件都会生成一个目标文件。链接器负责将这些目标文件合并成一个可执行文件或者共享库。一些大型项目几十万行代码,总不能每个功能都写在同一个文件中吧?
解决外部依赖问题:
在编写程序时,可能会依赖于第三方库或者系统提供的标准库。链接器会将这些外部依赖项与程序的目标文件进行链接,以确保程序能够正确地调用这些外部函数和访问这些外部变量。
优化代码大小和性能:
链接器还可以对目标文件进行优化,例如去除未使用的代码、合并相似的代码块等,以减小程序的体积(动态编译)并提高执行效率。
如何链接的(先简单介绍下)
链接的本质是拼接各个模块;比如 main 函数中调用了 hello.c 中的hello() 函数, main 函数必须知道 hello() 的地址,而模块是各自编译的,main 并不知 hello函数地址,于是 就先随便置一个地址,等链接的时候再替换,举个例子:
先直接将main单独 编译成 obj 文件,反汇编,此时 callq 调用的函数只是个 偏移量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| hrp@ubuntu:~$ cat main.c
#include "hello.h"
int main() {
hello();
return 0;
}
hrp@ubuntu:~$ gcc -c main.c
hrp@ubuntu:~$ objdump -d main.o
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: b8 00 00 00 00 mov $0x0,%eax
9: e8 00 00 00 00 callq e <main+0xe>
e: b8 00 00 00 00 mov $0x0,%eax
13: 5d pop %rbp
14: c3 retq
hrp@ubuntu:~$
|
生成 hello.o 文件
1
2
3
4
5
6
7
8
9
10
11
| hrp@ubuntu:~$ gcc -c hello.c
hrp@ubuntu:~$ objdump -d hello.o
0000000000000000 <hello>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # b <hello+0xb>
b: e8 00 00 00 00 callq 10 < +0x10>
10: 90 nop
hrp@ubuntu:~$
|
main.o 和 hello.o 链接起来(gcc 背后会调用ld 命令 );反汇编可以可能到是,两个 obj 文件的函数拼接成一个文件,并且更新了 main中 callq 的地址,此时的地址才是真正调用的地址,这个过程也叫重定位;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| hrp@ubuntu:~$ gcc hello.o main.o -o main
hrp@ubuntu:~$ ./main
ddHello, world!
hrp@ubuntu:~$ objdump -d main
.....
000000000000068a <hello>:
68a: 55 push %rbp
68b: 48 89 e5 mov %rsp,%rbp
68e: 48 8d 3d bf 00 00 00 lea 0xbf(%rip),%rdi # 754 <_IO_stdin_used+0x4>
695: e8 b6 fe ff ff callq 550 <puts@plt>
69a: 90 nop
69b: 5d pop %rbp
69c: c3 retq
000000000000069d <main>:
69d: 55 push %rbp
69e: 48 89 e5 mov %rsp,%rbp
6a1: 48 8d 3d ba 00 00 00 lea 0xba(%rip),%rdi # 762 <_IO_stdin_used+0x12>
6b7: e8 ce ff ff ff callq 68a <hello>
6bc: b8 00 00 00 00 mov $0x0,%eax
6c1: 5d pop %rbp
6c2: c3 retq
|