rclone拷贝桶对象失败定位过程
Last updated on 8 months ago
背景
某客户 有一套杉岩的对象存储环境(医疗图片),里面的桶容量快满了,于是想把这桶的数据迁移到 我们的集群,于是rclone 工具将 衫岩的的数据拷贝过来,但是总是失败。
问题
有少数的对象无法拷贝,rclone 显示报错(BadDigest),从客户描述 就是直接使用 rclone 命令,发现总是有一部分对象无法拷贝到 我们的对象存储上? 怀疑 是我们的存储有问题?

定位过程
从客户发来的rclone 日志来看 ,出现报错都是 BadDigest ,初步分析,大概是 MD5 校验失败, 但这信息并不足以证明 是客户那边的客户有问题还是我们存储有问题
本质上这是一个上传对象失败的问题,我们先排除rgw网关是否有异常
先询问客户是往那个网关 做拷贝的,从客户给的 rclone 日志找到失败的时间点 ,再从rgw日志找,发现都是 status 都是400 以及 op status 为 2005 ( 这是关键点! )

知道了 op status 为-2005 ,看下代码这个含义是?
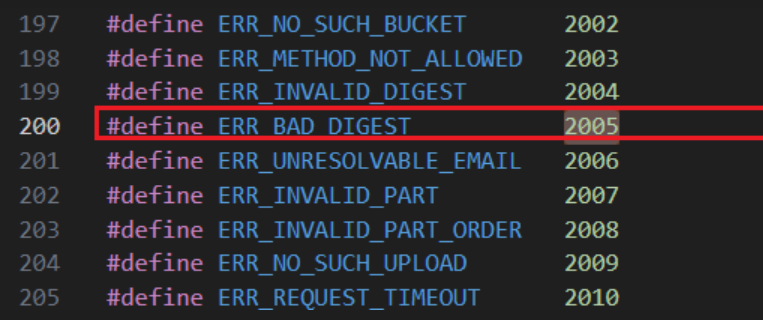 找到关键字 ERR_BAD_DIGEST ,因为这个是上传的流程,所以再上传流程中 搜这个关键子 ERR_BAD_DIGEST
找到关键字 ERR_BAD_DIGEST ,因为这个是上传的流程,所以再上传流程中 搜这个关键子 ERR_BAD_DIGEST
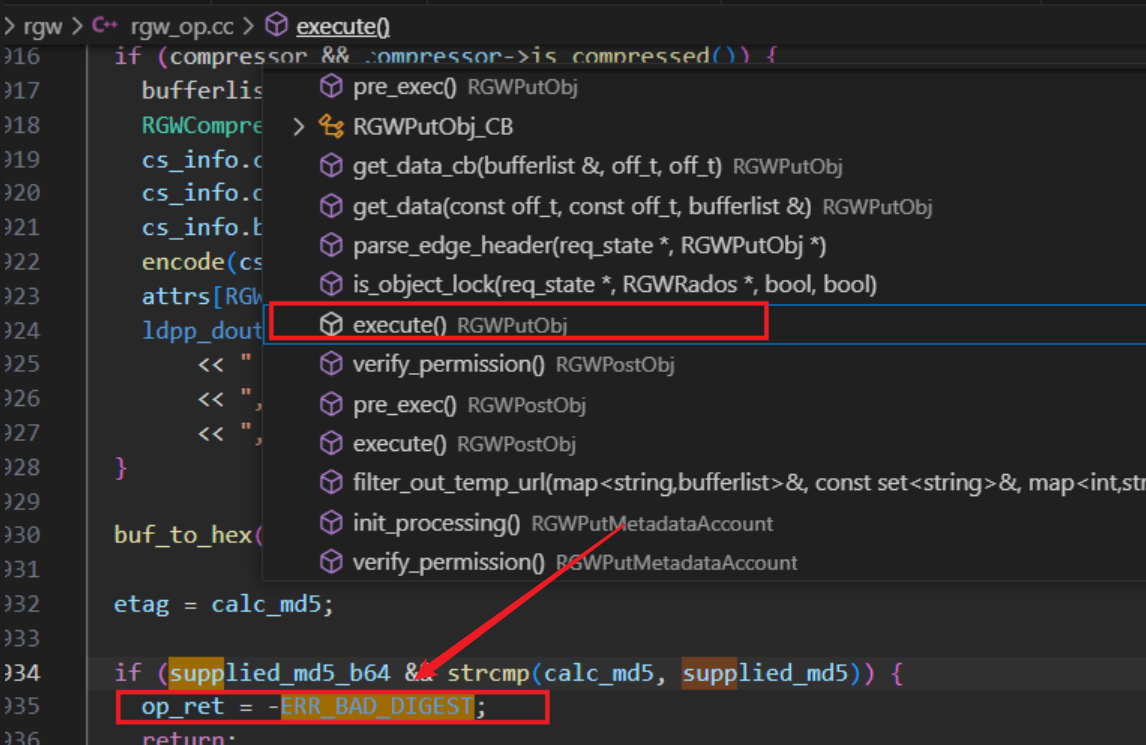
calc_md5 是rgw通过对象内容 计算出来的, supplied_md5 是通过请求带过来的,两者不同 ,所以导致400错误
难道是rgw 自己计算错了? 这种可能性很小; 更多的可能是 请求带来的 md5 本身就是不正确的? 但是为什么会不正确呢?
现在想验证下客户带来的md5和实际文件的md5是否匹配
在客户的允许下,开启了日志等级 ,看下请求带过来的 md5
以及手动算下这个对象的md5 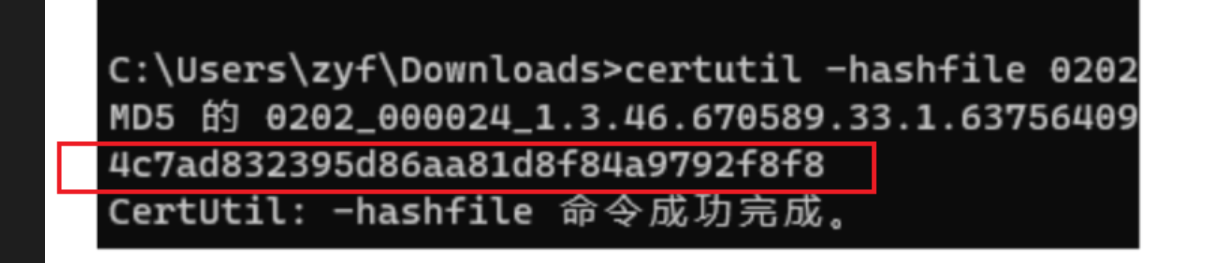
发现 真的是不一样, 现在可以确定这些失败的对象就是因为带过来的 md5是错的,和rgw实际算的不一致;
还有个问题是: 实际上已经拷贝过很多的对像都是成功的,只有 一部分对象无法拷贝,那是为什么呢? 难道是 rclone的bug?
现在推测是 : rclone 将对象的etag 作为 md5,(etag 在整体上传的时候是md5,而分段并不是 ),有些对象刚好就etag 不是md5,从客户的桶里看都是小对象的,并没有分段上传的
于是就在家里复现下:
手动将 对象的etag 修改,然后使用rclone 复制,看能否出现一样的错误
etag 是是以 xattr形式存放再bi池里面, 刚好rados 有相关接口可以直接修改 (我将 etag 最后的数字4 修改为 3)

修改之后,也是包一模一样的错误
现在可以证明 ,这个错误并不是我们存储的问题,也是不是md5计算的问题, 而是对象的etag 有错误
有什么办法避免这个错误吗?
把对象etag, 从新算一遍,再修改? 这个估计不行
让 rclone 不将etag 作为 md5,看来下 rclone 源码,rclone 机制是 head 下对象,获得元数据(包括etag),如果etag 未空的话 ,rclone 就会重新算一遍,于是就直接改了rclong代码,强制 rclone 算一遍,重新编译,后面也达到了预期效果;
其次也可以用nginx 做网关的代理,把请求头 etag 过滤掉,在转发给 rclone
结论
杉岩那边的对象 etag 不对,rclone 又将这个 etga 作为md5作为请求发过来,rgw这边自己算了一遍,发现不匹配造成的404错误
为什么他那边的etag 不对呢? 目前猜测是 客户业务 pacs , 医疗图像的,他们上传的时候 就对图片做了一次md5, 上传图片后可能会对图片操作,比如加水印什么的,这样导致图片内容有变,从而导致实际的md5 和 etag 不同 (按道理来说流程应该是操作处理完后还要再算一次md5的,不过这也不是我们关心的了)